Brief talk at Cloud Native @Scale, May 11, 2021, 5p PDT
Code for the demo for this talk lives on GitHub here.
Abstract
Going cloud-native is about how we design our applications, not just how we deploy them — and one key choice in distributed systems design is how our applications interact with each other. Request/response-based protocols are ubiquitous in software today, but the industry is still early in adopting event-driven approaches, which offer compelling advantages for highly distributed systems. This talk covers lessons learned from using event-driven patterns to scale real-world systems serving tens of millions of users and practical advice on how to use these patterns to make our applications more adaptable, reliable, and dynamically scalable.
Video
Slides and transcript
Hi everyone, I'm Melinda, and I'm here to talk about our favorite thing, cloud-native distributed systems. We'll do slides, then a live demo of a request/response architecture and moving it to an event-driven one.
Oh yeah: I work for eggy, where we love cloud-native distributed systems, and spent time at VSCO and some other places before that. (Hi Shruti!)

If you’re writing software that touches the internet today, there’s no getting around it: you’re building a distributed system.
Some parts of your software are running on mobile devices, or in a web browser, maybe; some parts are running on the server — probably many parts are running on many servers.
And all of these parts are calling each over a network, which may or may not be working, or might be running out of batteries or have an exploded hard drive at any point.
But your software is expected to stay up and running perfectly, even though any of its parts might be gone.
That’s difficult. Cloud-native software is inherently distributed, and distributed systems are difficult to design, build, understand, and operate.

But that’s why our jobs are fun.
When we build our systems, we’re designing for three main concerns:
First, reliability: how to make sure the system continues to work correctly and performantly, in the face of hardware or software faults, or human error.
Scalability: how to make sure we have reasonable ways to deal with our systems growing.
And maintainability: how to make sure that all the different people who are going to work on our system over time can understand and work on it productively.

But one overarching concern is how we keep complexity under control.
When we start building something, it can be simple and delightful and clean; but as our projects get bigger, they often become complex and difficult to understand.
And this complexity slows down everyone who needs to work on the system.
We end up with tangled dependencies, hacks or special-casing to work around problems, an explosion in how much state we’re keeping — you’ve seen this.
One way we try to manage complexity, as an industry, is by breaking our software down into
independently-deployable services.
This has many advantages: services can be worked on in parallel, each service can focus on a single domain, we have flexibility in how we solve larger problems, and so on.
But this is only true if we decompose our software in the right way and use patterns that fit our context.
If we aren’t careful, we could end up with software that’s still tightly coupled but now has an unreliable network between each piece of business logic, and is hard to deploy — and impossible to debug.

Okay, so, why is this?
One key property of our software architecture is how our microservices interact with each other. (Because we’ve broken it down, our software only works when multiple services work together.)
The default way that we do interaction nowadays is request/response, using synchronous network calls.
This model tries to make requests to a remote network service look like calling functions in a programming language, within the same process.
This seems convenient at first, but seeing remote calls as function calls is fundamentally flawed.
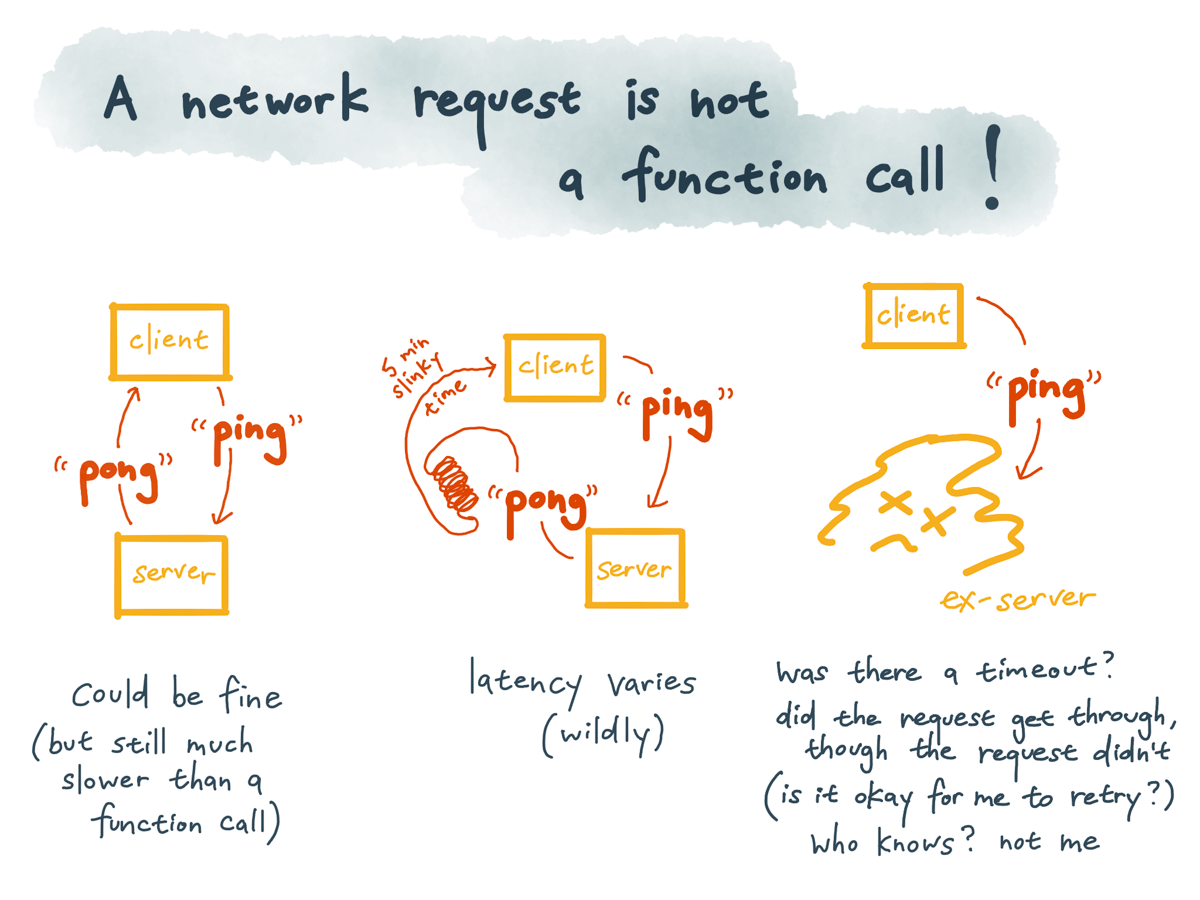
A network request is really different from a local function call.
A local function call is predictable and either succeeds or fails, depending on parameters that are totally under your control.
A network request is unpredictable: it could return successfully, albeit much more slowly than a function call. It could return successfully, but way more slowly — the network could be congested or the remote service could be overloaded, so it might take 20 seconds or 5 minutes to do the exact same thing. The request or response could get lost due to a network problem, or the remote service could be unavailable, or you could hit a timeout without receiving a result — and you would have no idea what happened.
If you don’t receive a response from your remote service, you have no way of knowing whether the request got through or not. Maybe the requests are actually getting through, and only the responses are getting lost — so it’s probably not safe for you to retry it, unless you’ve built in a mechanism for deduplication.
The cloud is a rough environment to be in, really different from a single computer.

And because of this, our distributed software that interacts using request/response can be incredibly hard to reason about.
Imagine you have on the order of 100 or 1000 services communicating with each other in a point-to-point way: how many different point-to-point connections that is.
And this is what a large distributed service architecture can look like. This is Netflix’s architecture circa 2015, from a re:Invent talk showing a network of services and their synchronous, run-time dependencies on other services. (Some people refer to this representation as a “death star” diagram.
You can see that as the number of services grows over time, the number of synchronous interactions grows with them somewhere between linearly and quadratically.
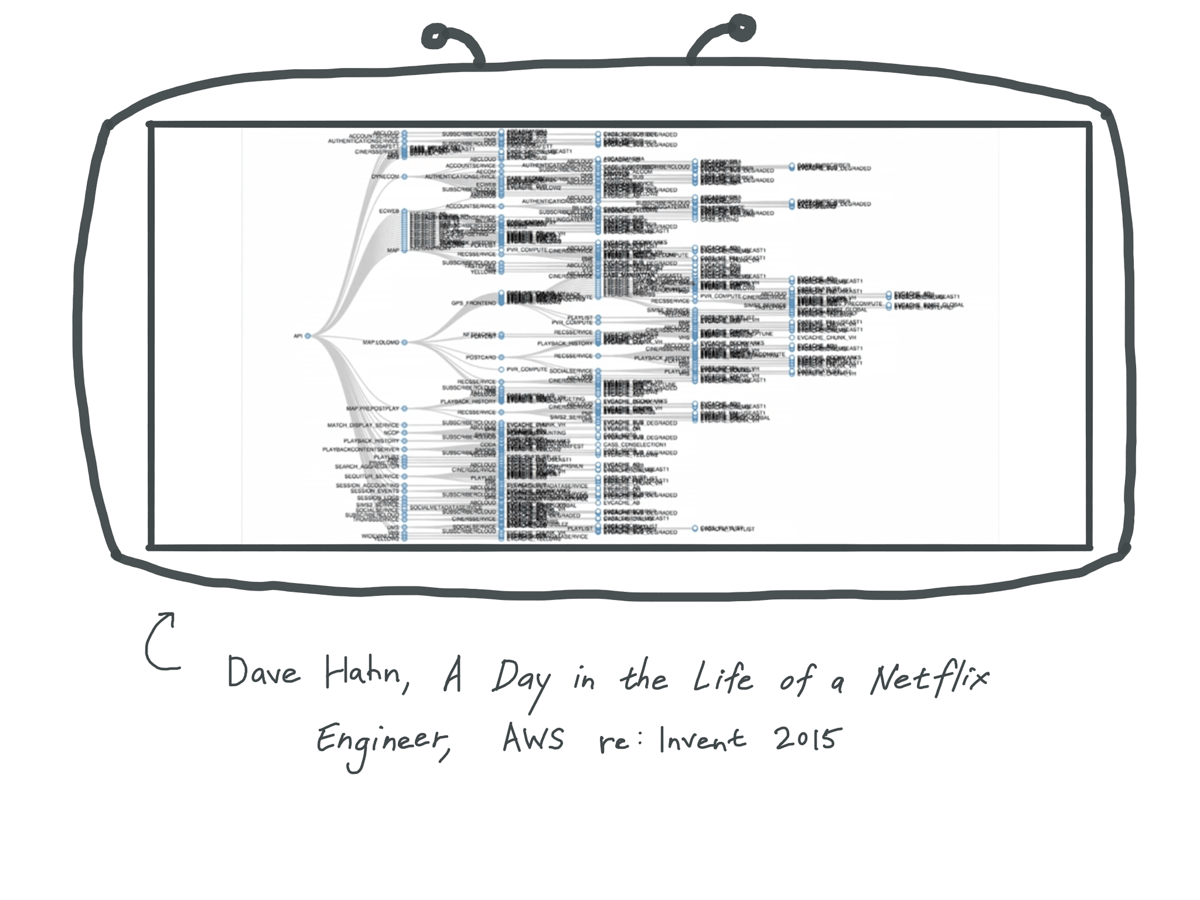
And if you zoom into one service, this is the call graph for a single Netflix service
from the same talk (the list of list of movies or lolomo service). These are all the services it has to talk to in order to return a response.
You can see that this one service depends on many other ones, and any of these n dependencies being down can cause availability issues for our one service.
And apart from availability, we have latency which grows with the depth of the dependency graph, we probably need to coordinate read times between when each of these is querying its datastore — and we are likely going to find it extremely difficult to reason about the state of the system at any point in time.
There’s a lot going on.

One solution to this availability problem, discussed in depth in this paper from Google, is just to make sure your individual services have significantly higher SLAs than what you need your system to have.
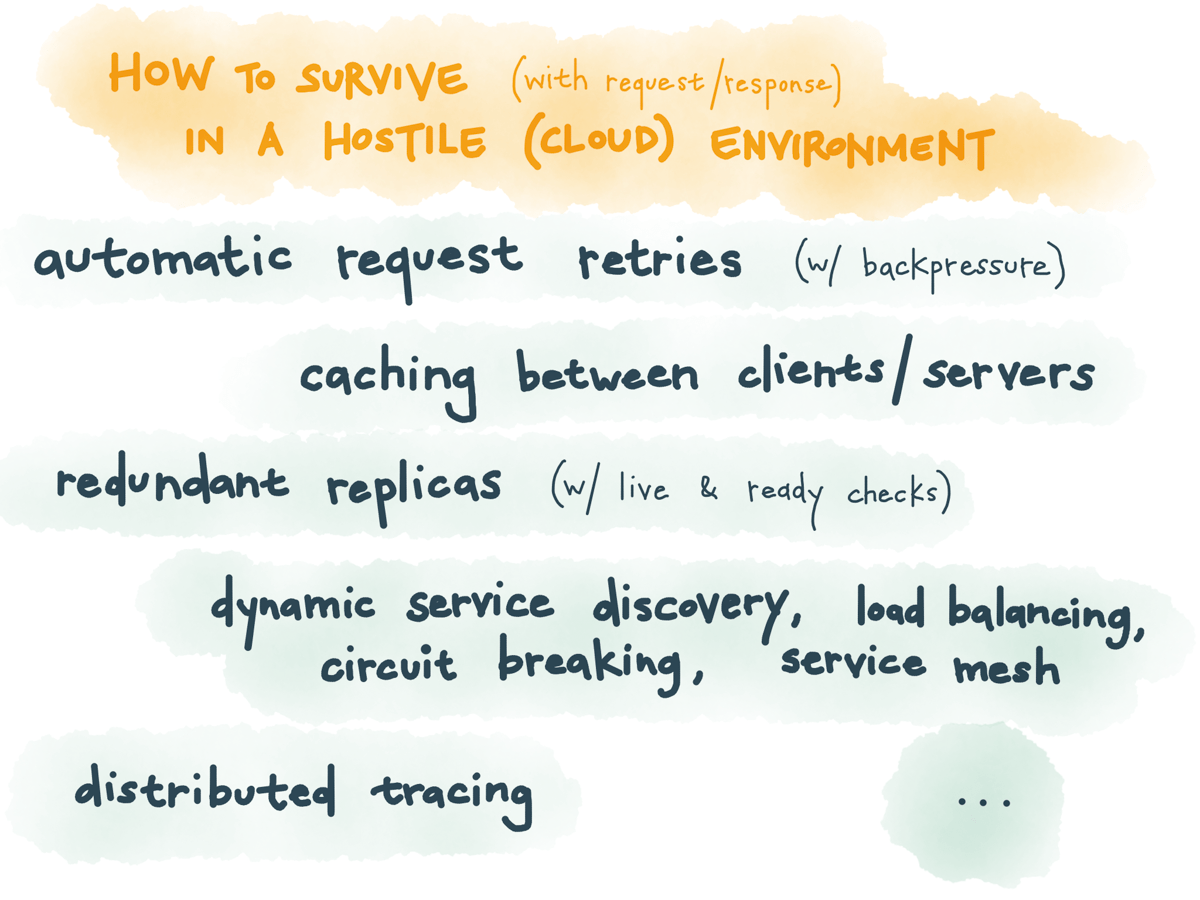
You can also do things like: make automatic request retries when you don’t get a response back, with backpressure; add caches in between clients and servers; have multiple redundant copies of services that can take requests when one copy is broken, with readiness and liveness checks to route to the right ones; dynamic service discovery, load balancing, circuit breaking, and other traffic control to make this all possible; service meshes like Linkerd and Istio to make this more transparent to the user.
These are standard cloud-native patterns, but these are standard patterns because trusting request/response to work, in a hostile environment like the cloud, is inherently risky.
And so much of the mind share in the microservices landscape — the libraries and tooling,
the documentation, blog posts and books and diagrams, assumes this model, of services calling each other synchronously.
And I think it’s a little unfortunate that we so often conflate the core values and goals of microservices with a specific model (request/response) for their implementation.
(This is also a hostile environment.)

But, what if, instead of patching these solutions for resilience on top of request/response, we could change the problem to a simpler one, by not binding our services together with synchronous ties?
The request/response model matches our sequential, imperative programming model of making in-place state changes on a single computer; and we’ve seen that it isn’t perfectly suited to a distributed environment.
But another programming style might match more-closely: functional programming.
Functional programming describes behavior in terms of the immutable input and output values of pure functions, not in terms of mutating objects in place.
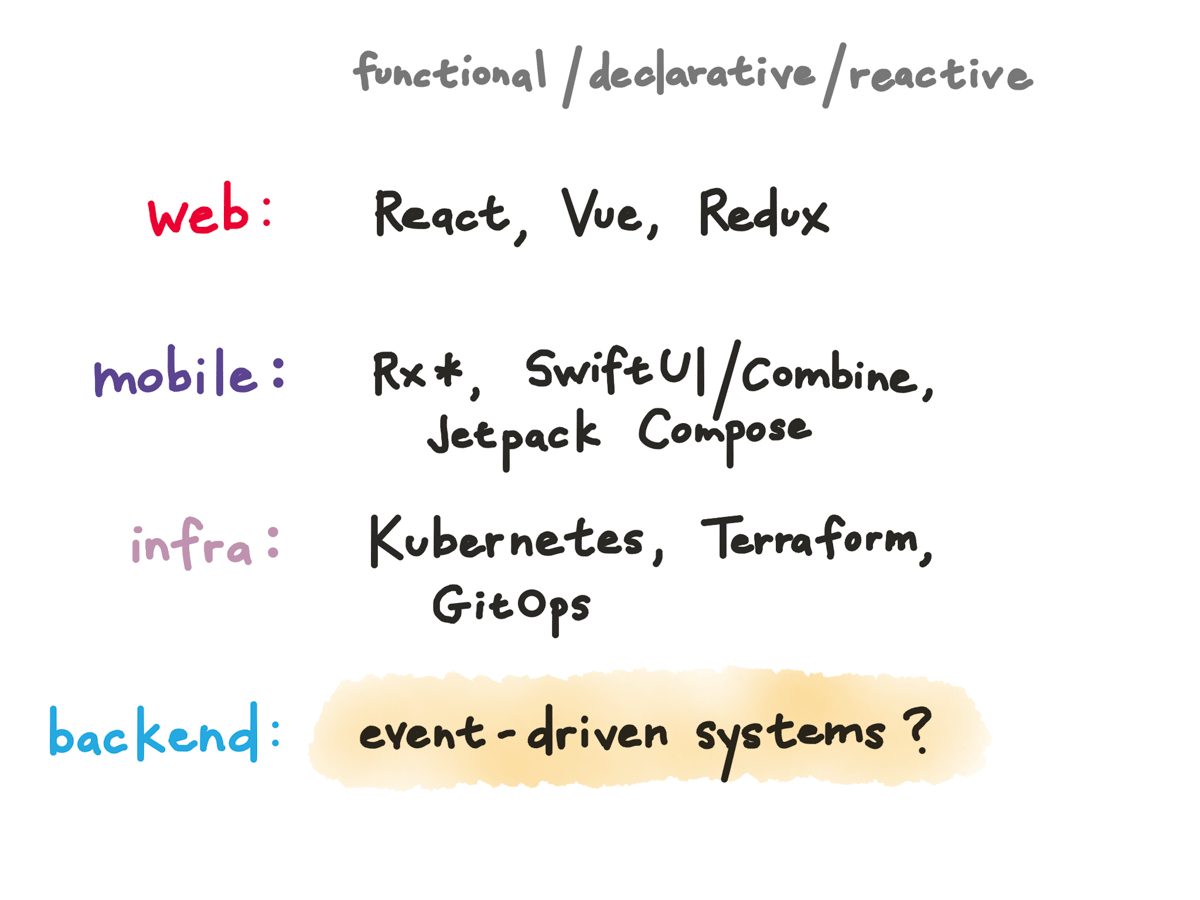
And we’ve seen in the last few years how thinking about things in a more functional way helps in other parts of the stack.
On the web, we’ve had reactive frameworks like React and Redux and Vue (and Elm before that) that almost everyone has shifted to after seeing how they can simplify things.
On mobile, the new generation of UI frameworks on both iOS and Android is functional and reactive, and we’ve had libraries for reactivity in business logic like Rx for a while, Combine more recently.
On the infrastructure side, we’ve seen how declarative APIs like Kubernetes and infrastructure-as-code tools like Terraform have made things so much easier to reason about and GitOps tools promise to take that further, but we’re still early in adopting this in backend application development.
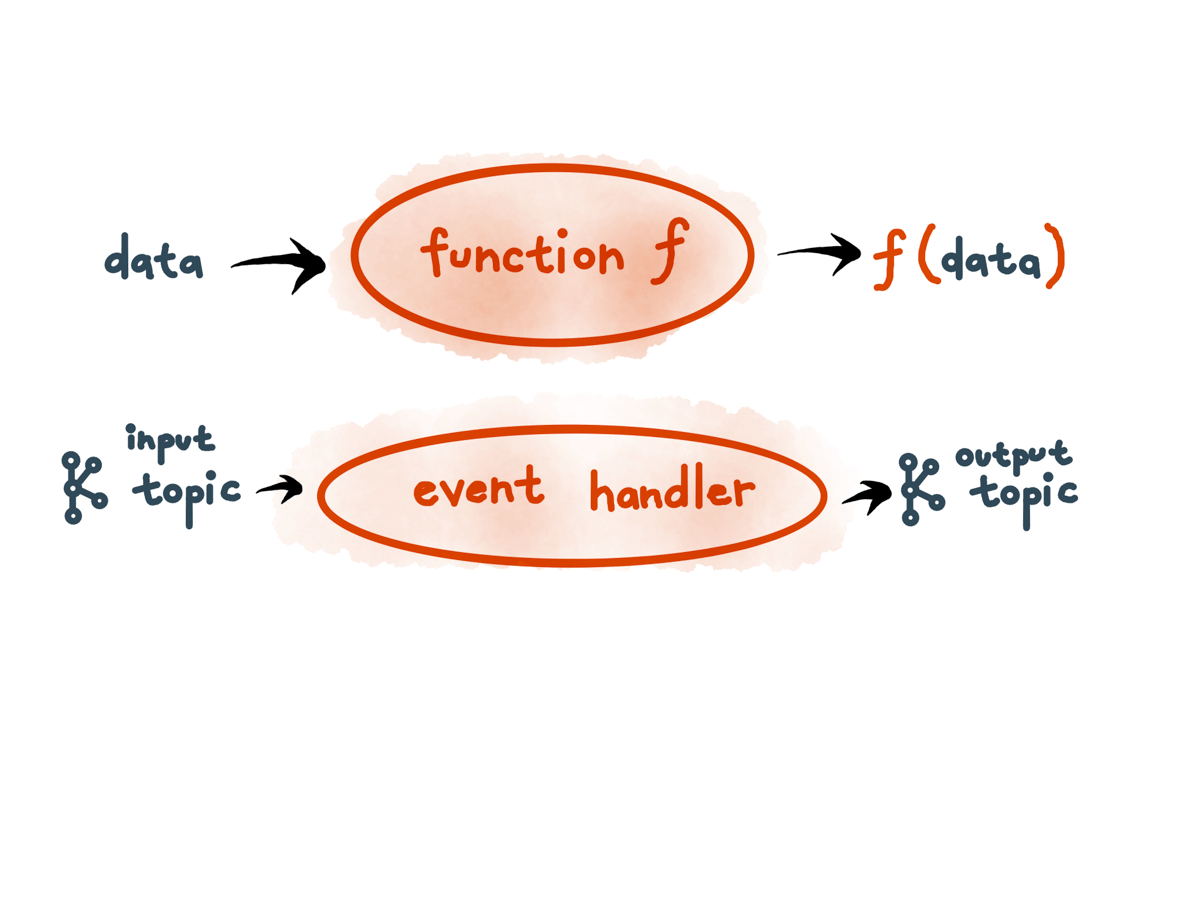
What would it look like if we extended the functional programming analogy to a microservices architecture?
This is basically event-driven architecture.
Like functional programming, it lets us know, consistently, the state of a system, as long as we know its input events.
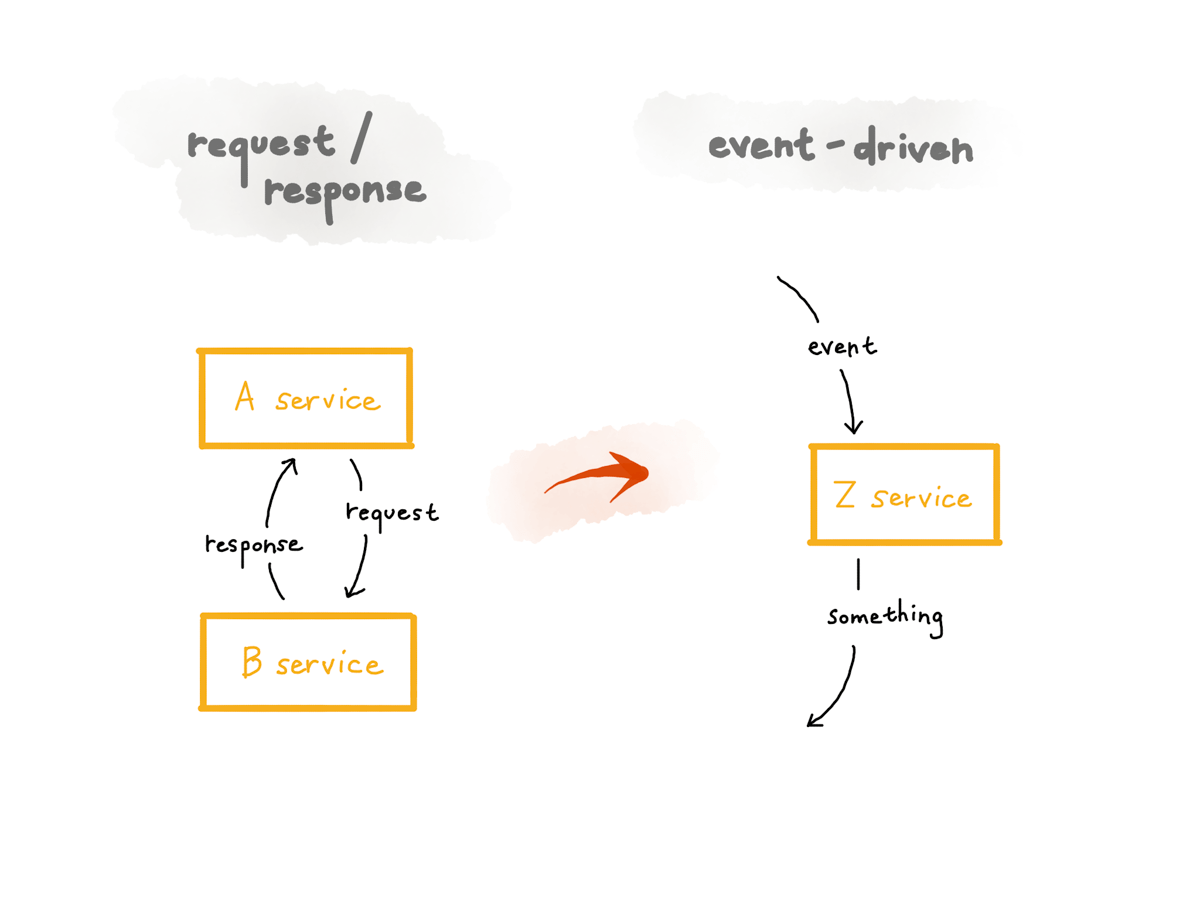
There are lots of different definitions of the details of what can be called an event-driven system, but the common thing is that the thing that triggers code execution in an event-driven system doesn’t wait for any response: it just sends it and then forgets about it.
So in this diagram, on the left, there’s a request and response: when a request is received, the receiving server has to return some type of a response to the client both the client and the server have to be alive, well, and focusing on each other in order for this to work.
On the other hand, on the right, there’s an event-driven service: the service that consumes the event does something with it, yes, but doesn’t have to send any response to the thing that originally created the event that triggered it. Only this service has to be alive for this code to be run; it doesn’t depend on other services being there. it’s not coupled to the thing that produced the event; it doesn’t have to know about the producer at all
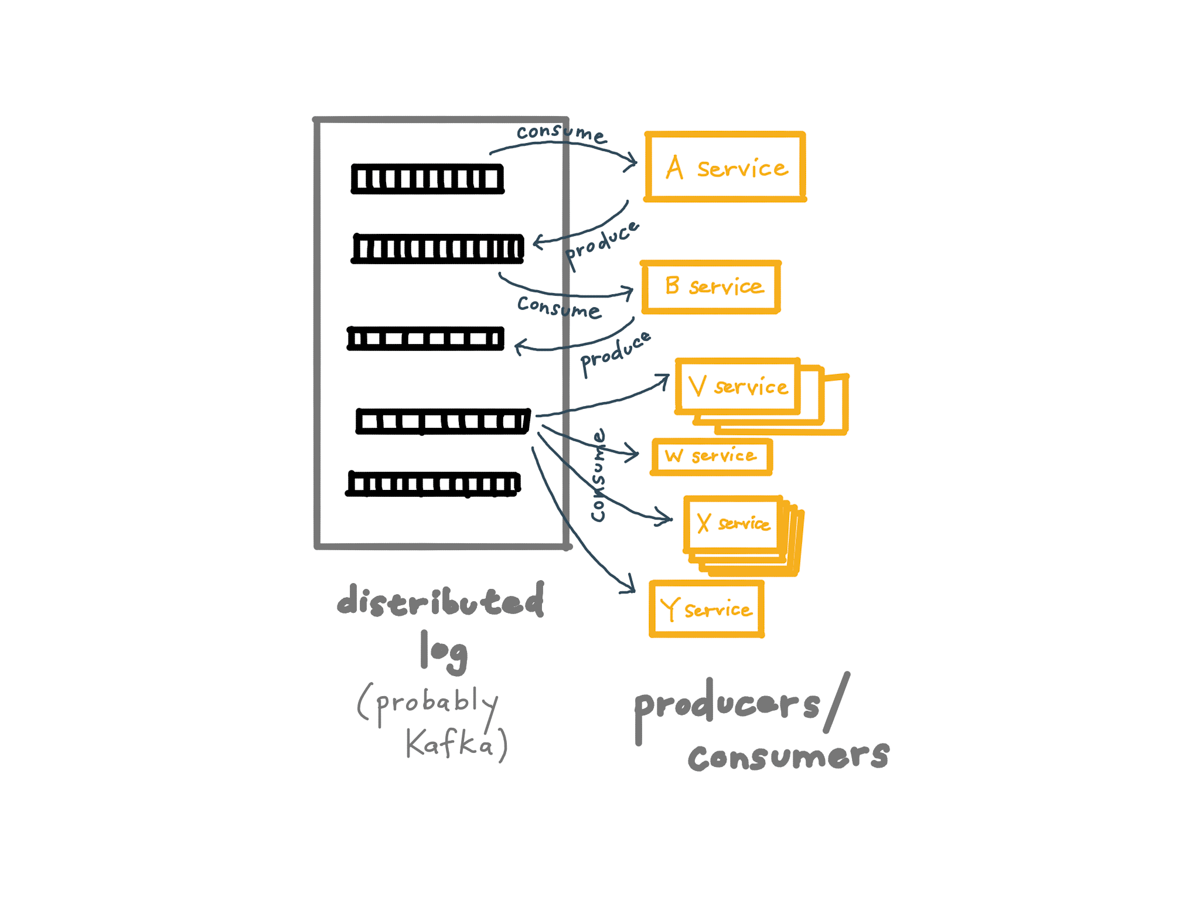
And the way this usually looks in practice is that we use a message broker or distributed log to store these events. These days this is usually Kafka or Kinesis.
Events are split into different streams called topics, which get partitioned across a horizontally-scalable cluster. Each of our services can consume from one or more topics, produce to one or more topics, or do both or neither.
And we’ll see this in a working example in a bit.
But why is this better? It’s a really different way of having programs interact and if we’re going to make this change, we’d better have some good reasons.

The biggest reason, I think, is the decoupling and easy composability this gives us.
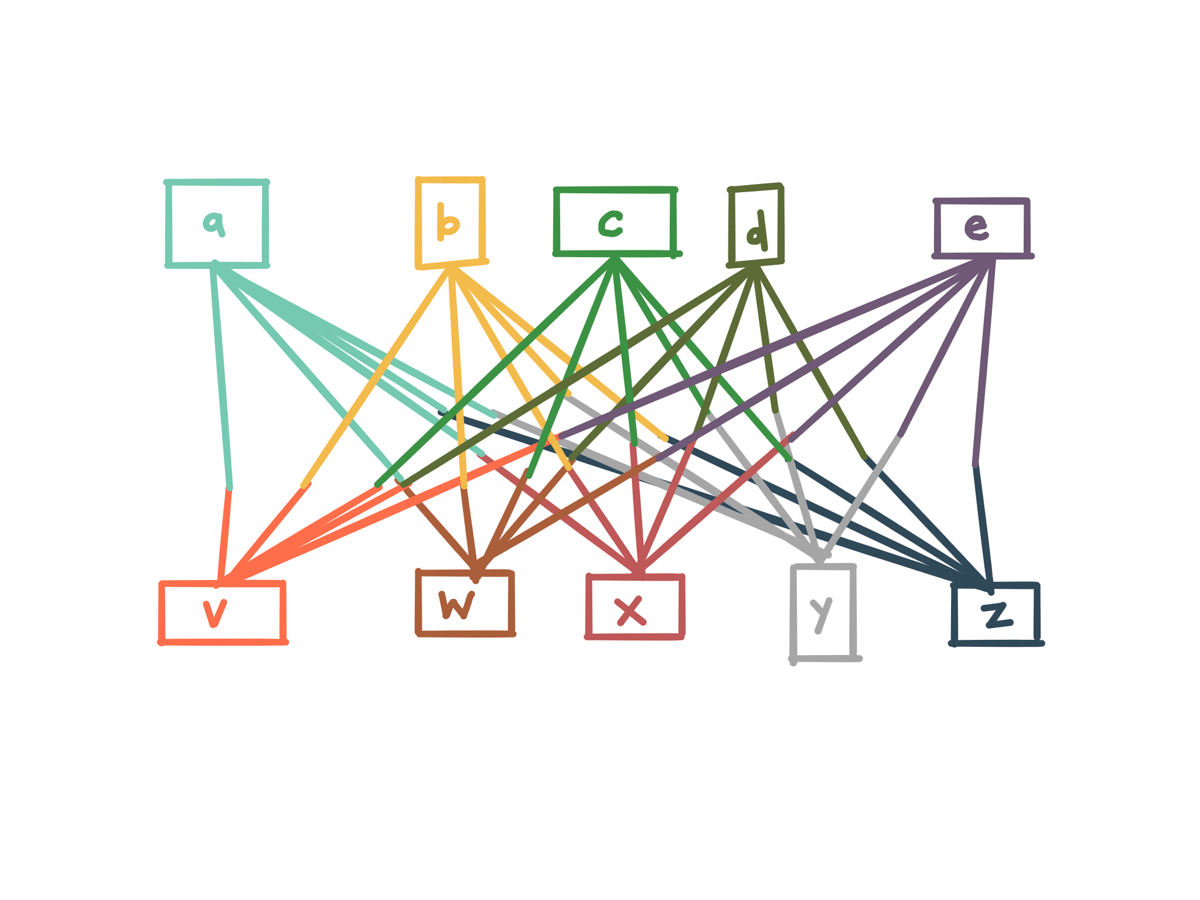
By getting rid of these point-to-point synchronous flows, our system can become much simpler.
Instead of having the work to add things scale quadratically, because every new thing has to be hooked up to every existing thing…
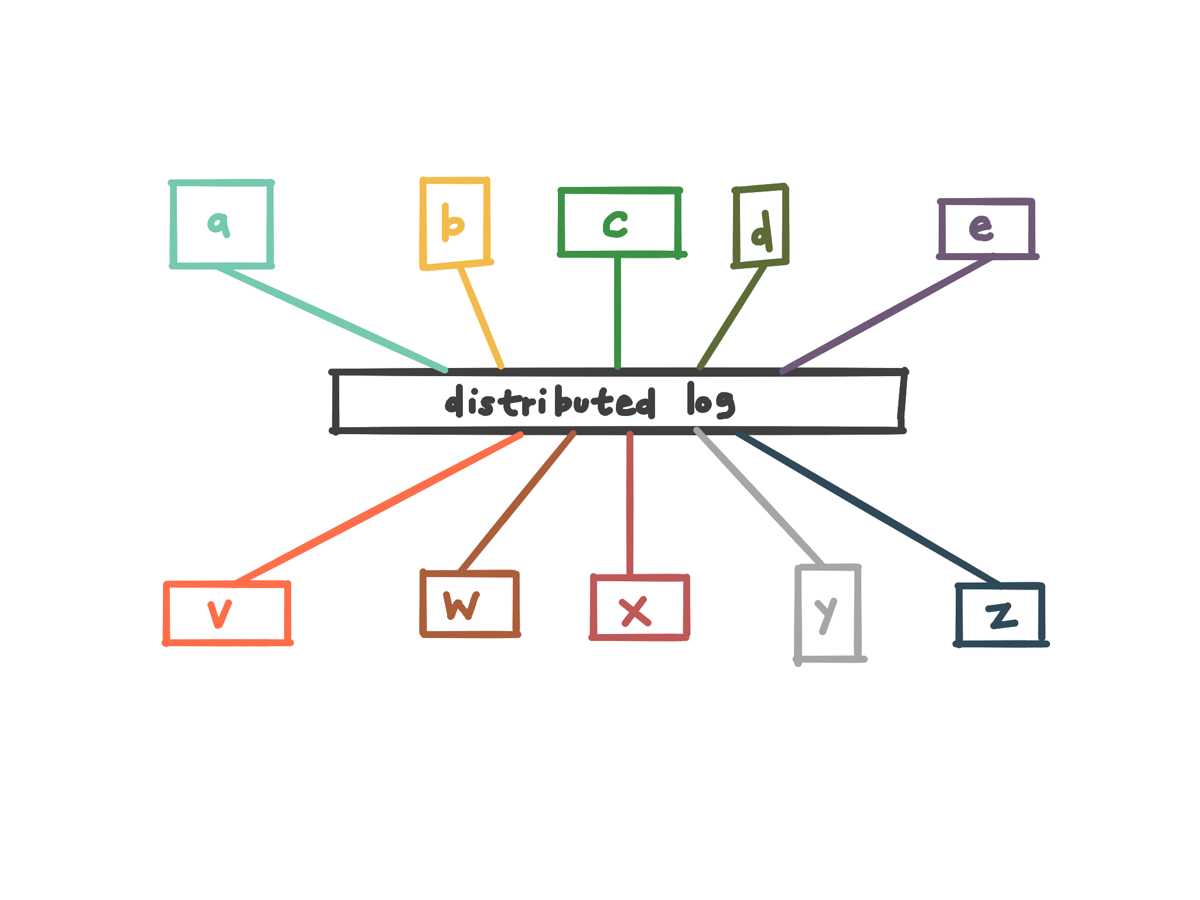
…it becomes a simpler task to plug new services in, or change services that are there.
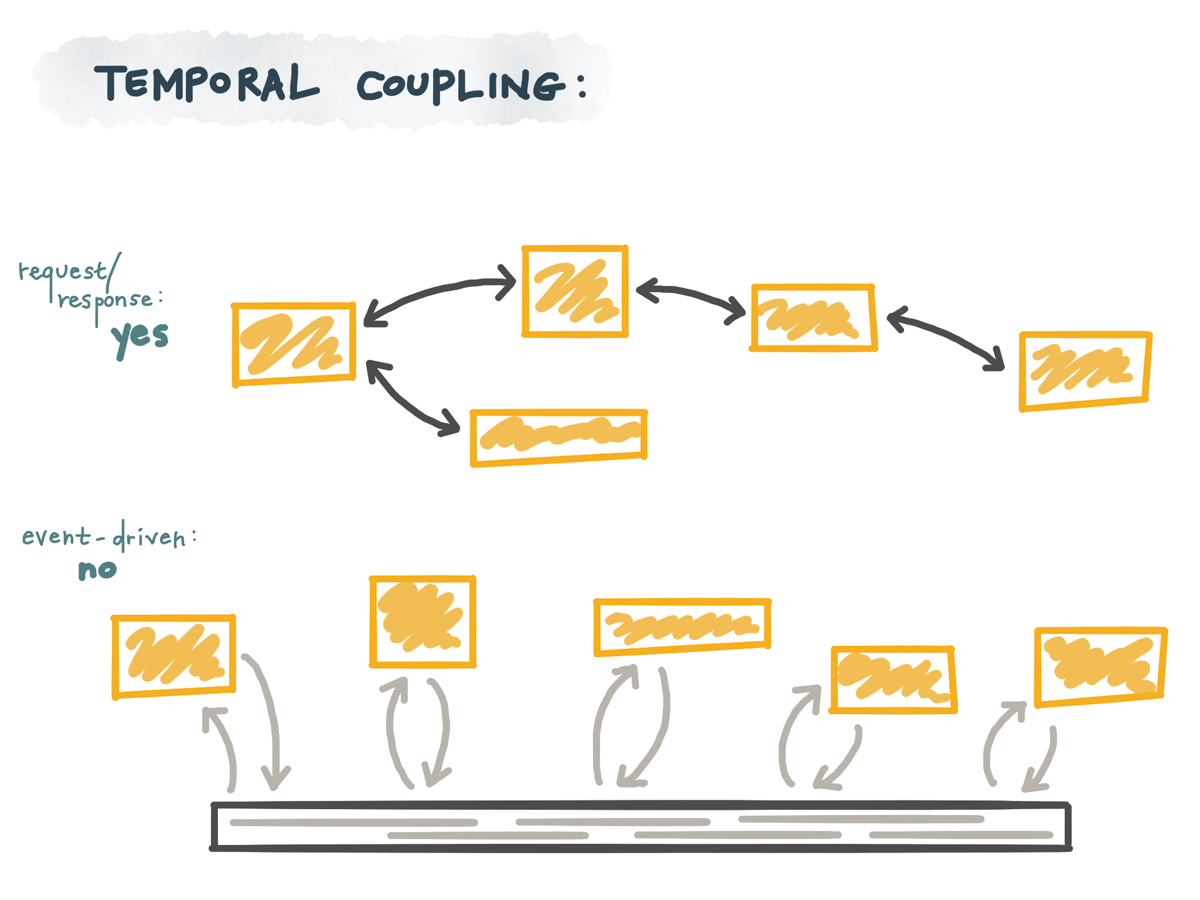
We can break these long chains of blocking commands, where one piece being down at any given time means all of these are unavailable.
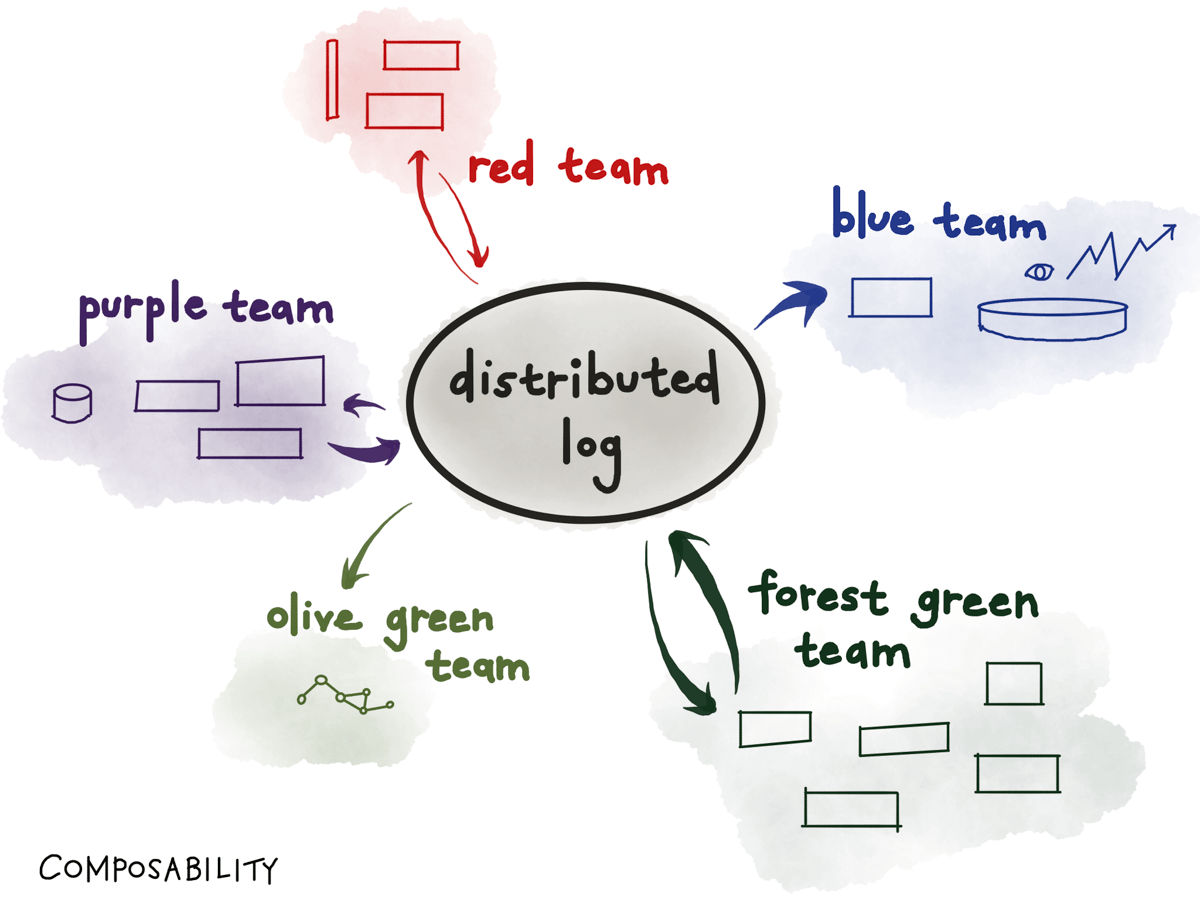
And zooming out to a whole organization, these design principles let us build composable systems at a large scale.
In a large org, different teams can independently design and build services that consume from topics and produce to new topics. Since a topic can have any number of independent consumers, no coordination is required to set up a new consumer. And consumers can be deployed at will, or built with different technologies, be it different languages and libraries or different datastores.
Each team focuses on making their particular part of the system do its job well.
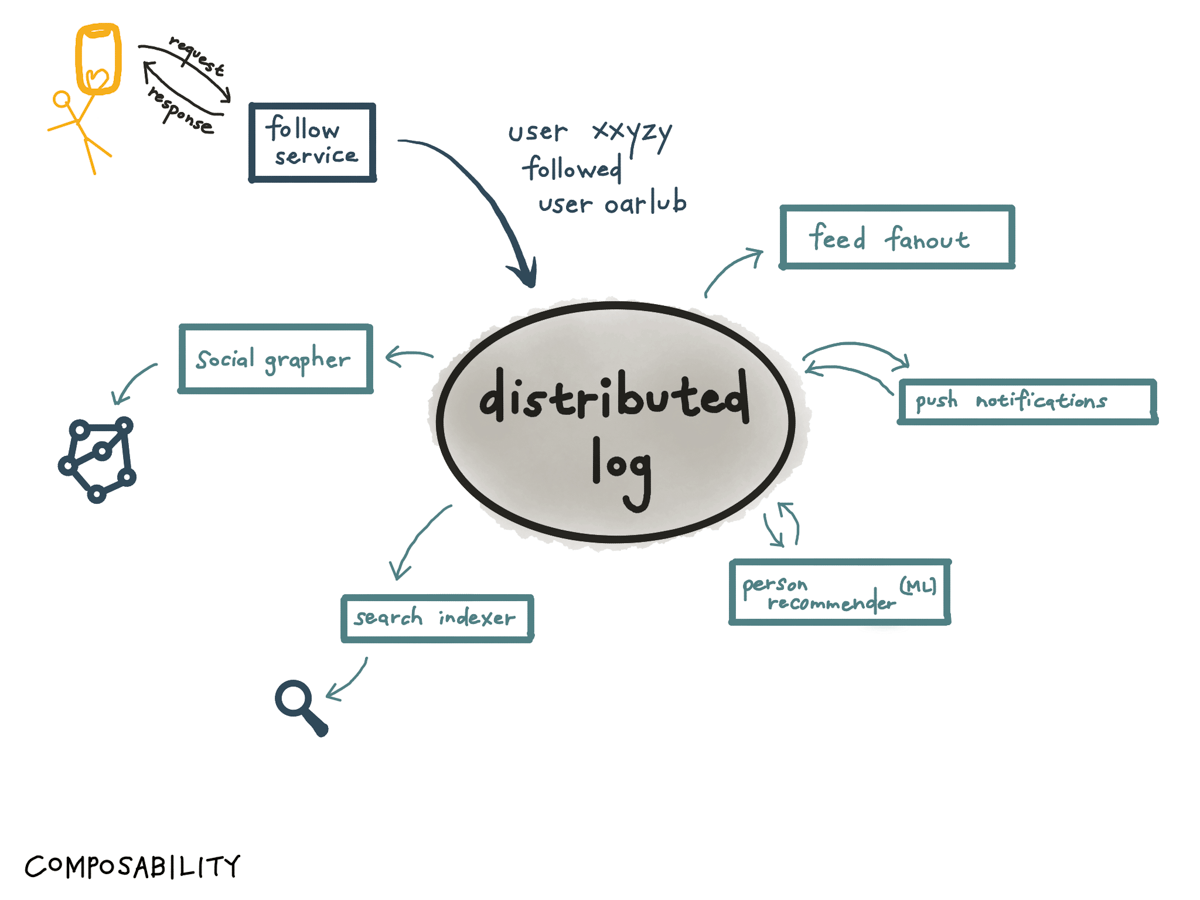
As a real-life example, this is how this worked at VSCO. VSCO is a photo- and video-sharing consumer platform where users have their own profile, and can follow other users and get their content in their feed (you know — a social network).
What happens if a user follows another user?
The first thing that happens is they hit a synchronous follow service, which then tries to get that information into the distributed log (Kafka) as soon as possible.
And once it’s there, it can be used for many things: it gets consumed by the feed fanout worker so the follower can get the followee’s posts injected into their feed; it gets consumed by the push notification pipeline so the followee can see they’ve gotten a new follower, and so on.
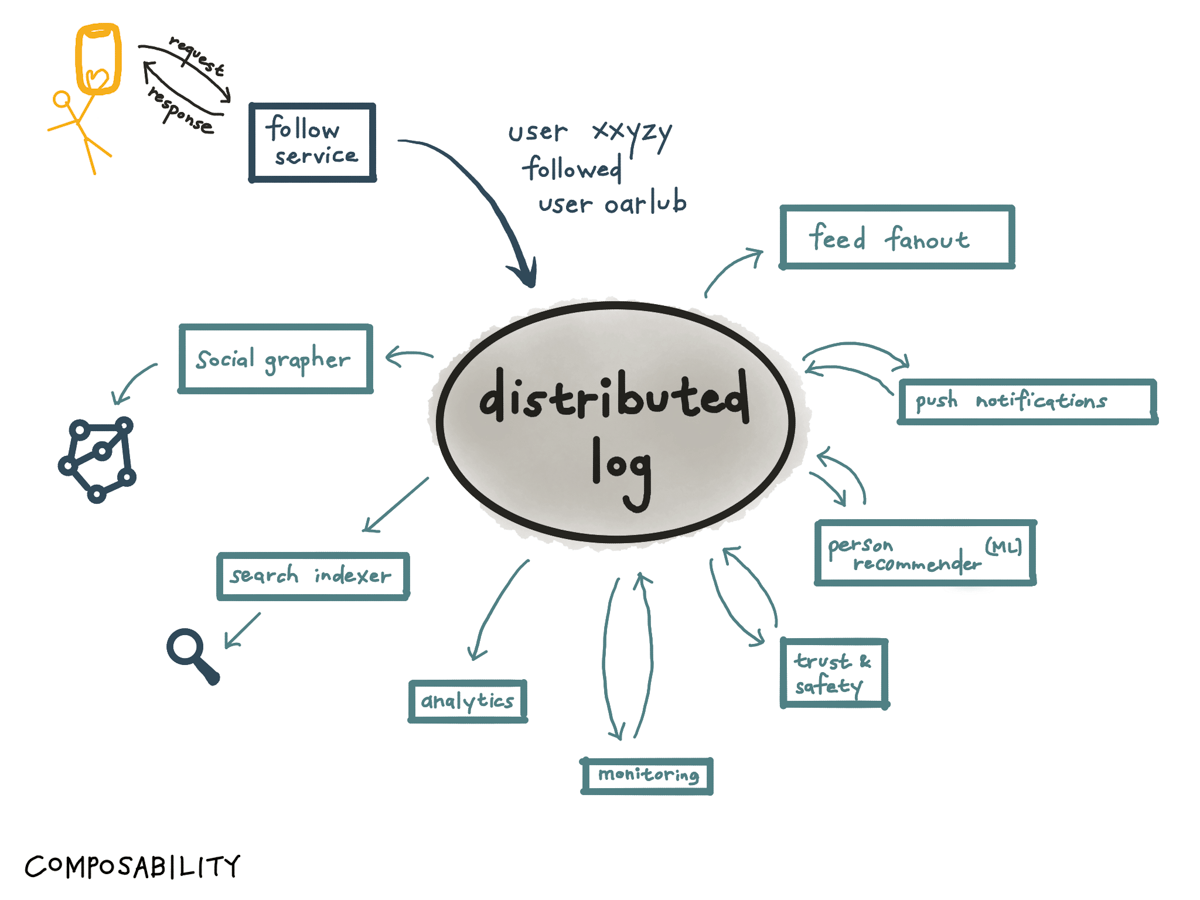
And the key is that you can keep on plugging more consumers. You could add monitoring, so you can see if the rate of follows goes way down (and business metrics might be affected by a change in our app design or something like that) — or if it goes way up, in case something weird is going on.
You could add an abuse prevention mechanism, to see if something weird is going on.
You could add analytics in case you need to make a report to Wall Street.
And so on.
All these systems can be developed independently, and connected and composed in a way that is and feels robust.

Another side benefit is that you get asynchronous flows for free.
It used to be that we’d need to do a bunch of orchestration to set up batch jobs with like Airflow or something, but if we handle the real-time case with events, then we can do offline jobs by default, just like any other consumer.

And this functional composition makes things easier to trace too.
There’s a central, immutable, saved journal of every interaction and its inputs and outputs, so we can go back and see exactly where something failed.
To get this with request/response, we’d have to invest a ton in a full distributed tracing system — and even then we might not see where latencies are hidden.
Another reason event-driven systems are helpful is that they can provide scale by default, and make some of the patterns we use for resilience in request/response service architectures unnecessary.

The distributed log acts as a buffer if the recipient is unavailable or overloaded, and automatically redelivers messages to a process that’s crashed and prevents messages from being lost; so this makes retries with backpressure and healthchecks less necessary.
The log prevents the sender from needing to know the IP address and port number of the recipient, which is particularly useful in the cloud, where servers go up and down all the time; so we don’t need complex service discovery and load balancing as critically.

Second: there’s what’s called “polyglot persistence” nowadays, where we use lots of different kinds of databases to serve different use cases.
There’s no single “one-size-fits-all” database that’s able to fit all the different access patterns efficiently.

For example, you might need users to perform a keyword search on a dataset
and so you need a full-text search index service like Elasticsearch.
You might need a specialized database like a scientific or graph database, to do specialized data structure traversals or filters.
You might have a data warehouse for business analytics, where you need a really different storage layout, like a column-oriented storage engine.
When new data gets written, how do you make sure it ends up in all the right places?

You could write to all the databases from a synchronous microservices — dual writes, or triple or quadruple writes — but we’ve seen how that is fragile.
It’s also theoretically impossible to make dual writes consistent without distributed transactions, which you can read about in detail in this paper.
So instead we can use event-driven systems to do what’s called change data capture. This is an old idea where we let an application subscribe to a stream of everything that is written to a database — and then we can use that feed to do the things listed on the last slide: update search indexes, invalidate caches, create snapshots, and so on.
There are open-source libraries for this now, there’s Debezium which uses Kafka Connect and databases are increasingly starting to support change streams as a first-class interface.
At VSCO, because we started doing this back in 2016 before there were common tools for this, we had our own version.
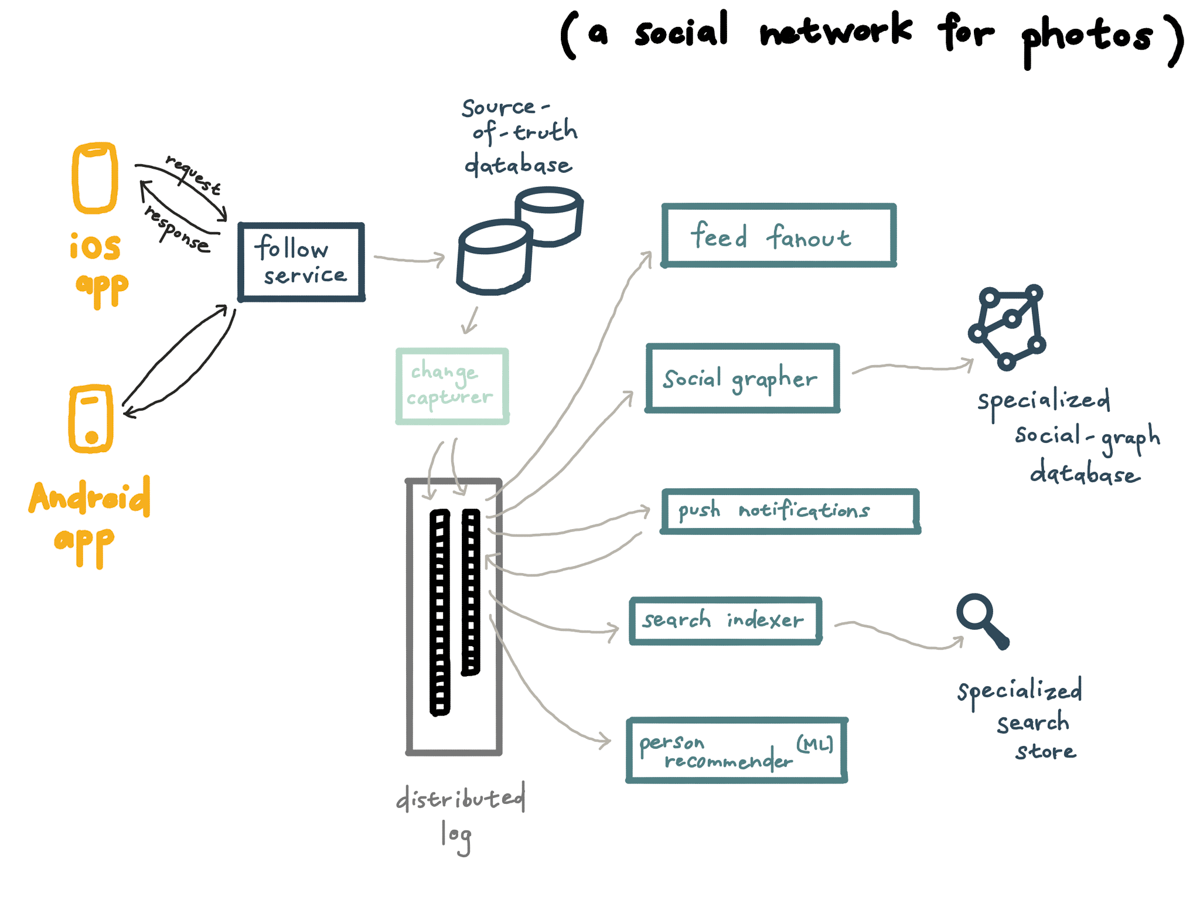
Going back to the follows use case, the way that the event gets into the distributed log in the first place is that the follows service writes to an online transaction database, say something like MySQL or MongoDB.
Then, our change data capture service writes every change to the distributed log, where any number of consumers can do whatever they want with it.
This ends up being a nice way to migrate off a monolith — you can let the monolith keep doing the initial database write, suck those writes into your event store with database change capture, and pull out all the reads and all the extra stuff the monolith does for every write into composable workers reading off the event store.
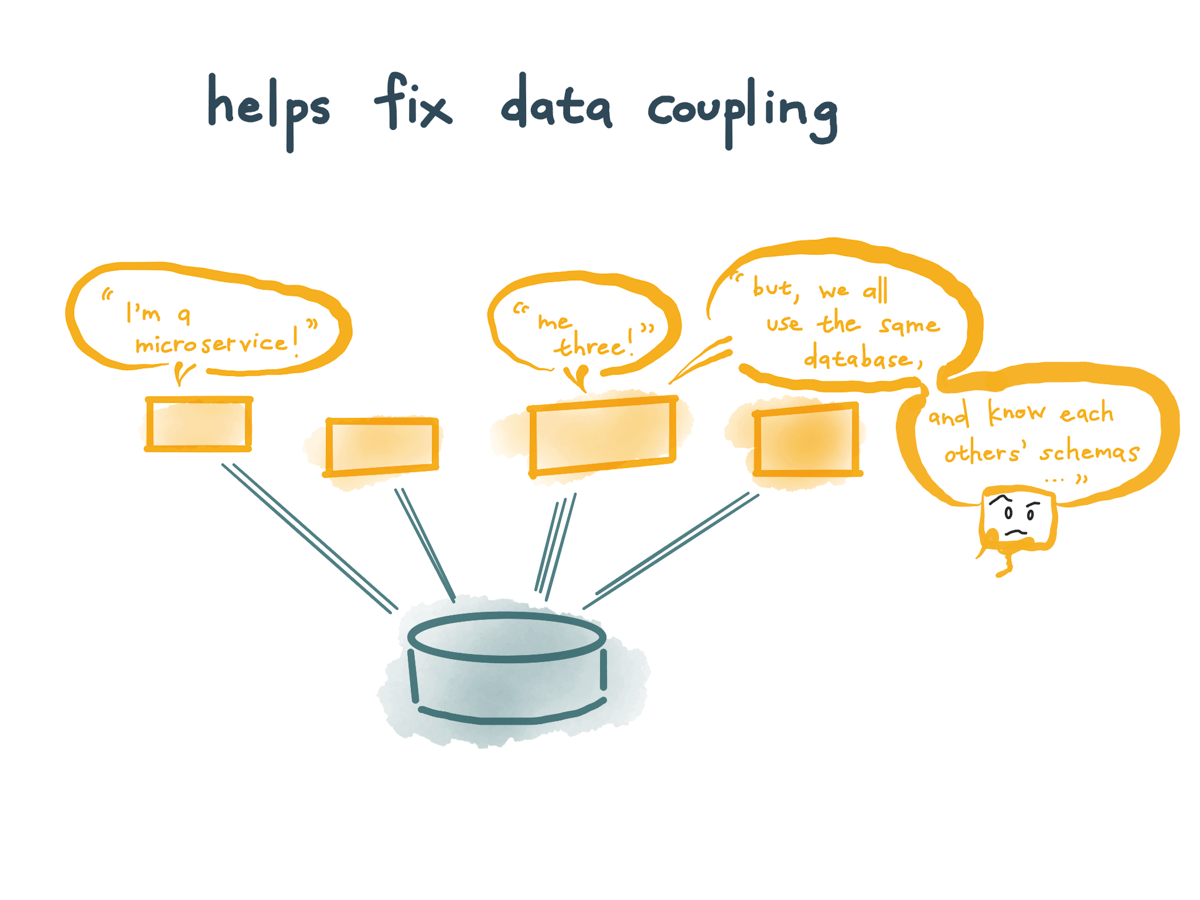
As a side benefit to this, this helps us fix one of the most common pitfalls in microservice architecture, where we have a bunch of independently deployable services but they all share a single database. This broad, shared contract makes it hard to figure out what effect our changes might have.
We would rather have our data not be so coupled but it’s hard to unbundle it.
Change data capture can make it much easier.

We also can save much richer data with event-driven systems, if we want to.
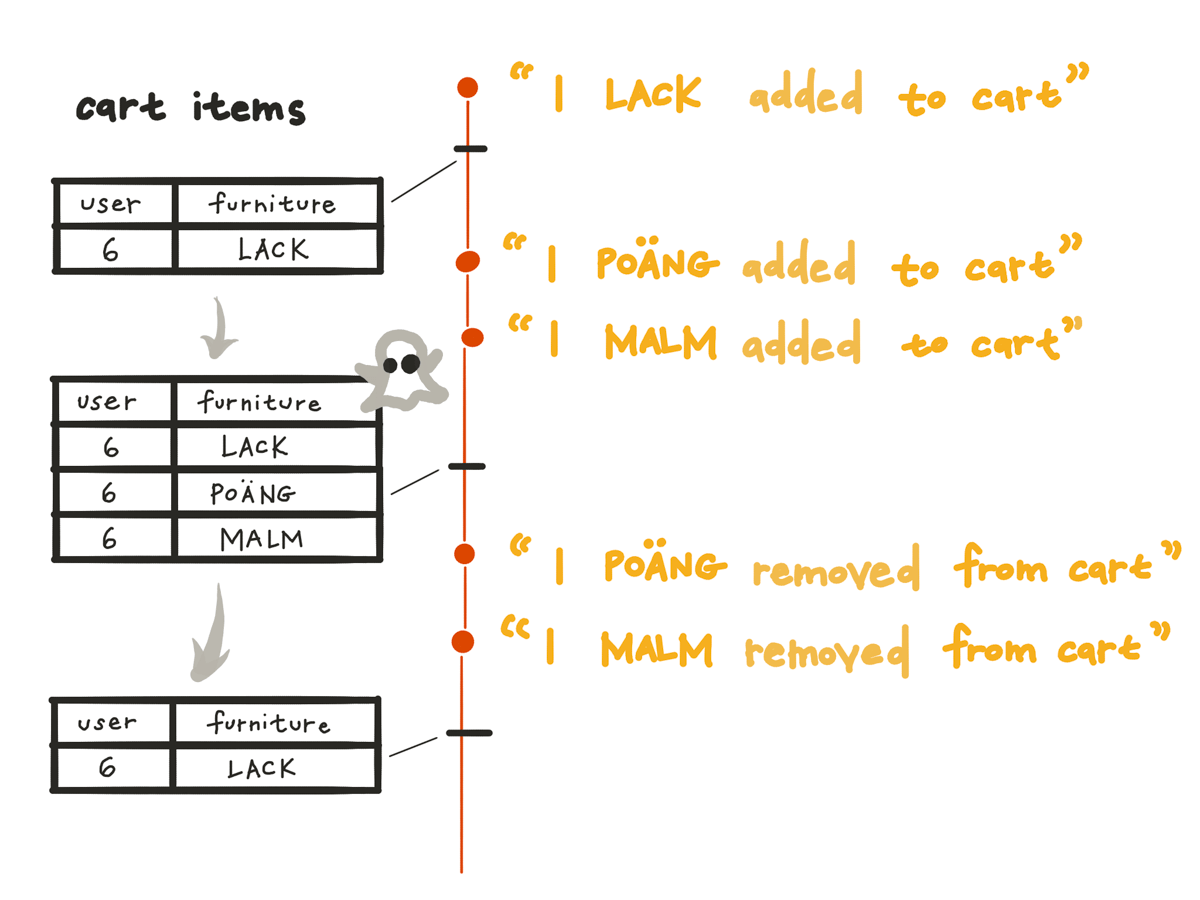
Writing data as a log can produce better-quality data by default than if we update a database directly,
For example, if someone adds an item to their shopping cart and then removes it again (we’re buying furniture), those add and delete actions have information value.
If we delete that information from the database when a customer removes an item from the cart, we’ve just thrown away information that might have been valuable for analytics and recommendation systems.

And this approach is usually given the name event sourcing, which comes from the domain-driven design community.
Like change data capture, event sourcing involves saving all changes to the application state as a log of change events.
But instead of letting one part of the application use the database in a mutable way and update and delete records as it likes.
In event sourcing, our application logic is explicitly built on the basis of immutable events.
And the event store is append-only, and usually updates or deletes are discouraged or prohibited; and then to get a copy of your current working tree you’d aggregate over all the diffs over time.
In a fully event-sourced system the current state is derived.
Both this and the mutable version are valid approaches, but they come with slightly different tradeoffs in practice.
Regardless of which one we use, the important thing is to save facts, as they are observed, in an event log.

And there’s a bonus reason which falls out of all the other reasons, which is that this is really good for machine learning.
There’s this idea of “software 2.0,” which is that, increasingly, we’ll want to plug machine-learnable programs into different parts of our software where we can get better results than by hand-coding a program.
Say, we’ll tune a database index with a model here, or decide whether this request is from a legitimate actor there.
And inserting ML like this will really just not be tractable if we do this in a point-to-point, request/response way. Our software will become totally incomprehensible.
But if we’ve already switched to using an event-driven system where the pluggable data integration is already there for us, adding ML will become much less painful.

That said, there are some things to watch out for with this.

The biggest one is concurrency management: if we have distributed data management, how do you make sure you read all the implications of your writes?
We don’t have time to go into this, because it’s a deep theoretical issue and request/response doesn’t really solve it either — the Martin Kleppmann paper mentioned earlier goes into it in great depth.

You do have to be thoughtful about your schemas — how you choose to structure your event data.
Since the events are now your interface, you have to handle backward and forward compability with them like you would with an API.
Empirically I’ve found this less work than versioning request/response APIs, but it’s something to think about.
There are mature systems like protobuf and Avro for this that are quite good — would just recommend using a data serialization system, and not trying to handroll something on top of JSON or something here.

As in request/response systems, privacy and data deletion are key — with GDPR, CCPA, and other privacy regulations (and also just doing right by our users), when we delete a single piece of data, we want to make sure to delete all pieces of data derived from it — which might now be in many datastores.
Event-driven processing can make it easier to perform this deletion, but might also make it more likely that you have more data to delete.

The biggest gotcha, though it’s becoming less and less true, is that event-driven interactions are not the norm yet.
And so there are fewer libraries and tools and blog posts and example repos about this than about request/response architectures.
But running Kubernetes or using infrastructure as code wasn’t the default a few years either, and we’ve seen how the industry moving to it has made our lives easier.

On GitHub we have a full-stack (infra/backend/web) working version of a breakfast delivery service with two different architectures: first, we run it on request-response microservices, then on event-driven microservices.
It’ll be fun to poke around, we promise.
(Like this content? 🥞 Subscribe here to be notified about future updates!)